一日一回 大きくてスパースなファイルを gzip -d してるあなたへ
忙しい人向け
タイトルの通りですが、N GBオーダのスパースなファイルを gzip -d して開発マシンに解凍している人に向けた spdc というツールを作成しました。 このツールを使うと、gzipで圧縮されたファイルをスパースなファイル として解凍できます。
スパースファイルとは?
初めにスパースなファイルについて説明します。
面倒なので ChatGPT-4.0 に任せます(隙あらば課金自慢)
スパースファイルとは、実際には空であるが、システムに対してはデータが存在するかのように振る舞う特殊なファイルのことを指します。この種のファイルは、大量の0の連続部分(つまり、何も情報を持たない部分)をディスク上に実際には書き込まず、空いていると報告することでディスクスペースを節約します。そのため、非常に大きなファイルを作成する場合でも、スパースファイルを使用すれば実際には少量のディスクスペースしか使用しないことができます。 例えば、100GBのスパースファイルを作成したとします。しかし、そのうち実際にデータが書き込まれている部分は1GBだけだとします。この場合、そのファイルは100GBのサイズがあるとシステムに報告しますが、実際にディスク上に占有しているスペースは1GBだけです。このようにスパースファイルは、ディスクスペースを効率的に利用するための手段となります。 しかし、すべてのファイルシステムやアプリケーションがスパースファイルをサポートしているわけではないため、スパースファイルを取り扱う際には注意が必要です。スパースファイルをサポートしていないシステムでスパースファイルを扱うと、ファイルが実際のサイズ(この場合、100GB)に膨らんでしまう可能性があります。
らしいです。非常に的を射てるというか自分より詳しいまであります。
なにが嬉しいの?
あるあるなのは ubuntu-2204.img.gz など 仮想マシンイメージや、raw イメージをgzipで受け取りそれを解凍する際にディスクフルになってイラッとしがちです。
今回は gzip -d の代わりとなるツールを作成しました。
ちなみに README もChatGPTに書いてもらいました。実質コピペしかしてないまであります。
以下実際に利用したイメージです。READMEにほぼ同様のこと書いてます。
spdc(本ツール) を利用した場合


見てもらいたいのは du -h の結果です。これは実際にストレージとして利用しているサイズになります。 spdc を利用して解凍した場合は、ファイルのサイズとしては 40 GB ですが、実際にディスク容量を消費しているのが 1.8 GB というかなりディスクに優しいデータになっていることがわかります。
書き込み時に並列化しているので spdc で解凍した方が早いのですが、 自分が gzip -d のオプションを知らないだけ説が濃厚です。 また、cp コマンドを利用することで、 スパースなファイルに変換できるらしいということは知っているのですが、調査するより作った方が早かったので作りました。
実装について
あんまり語ることがありません。ChatGPTにgolangでスパースなファイル作れたりする?と聞いたら作れるらしいと知ったので、開発しました。 大事なのはここの部分だと思います。

さらにすることがあるのか?
他の圧縮に対応
内部的には各圧縮アルゴリズムの io.Reader でラップしたものを DecompressSparseReader に渡せばいいので、だれかPR送ってください。 いまさらだけど、ここ Reader じゃないっすね。Copy とかそんな感じの名前の方が良さそう。。。(いつか直す)
func DecompressSparseGzip(src, dst string) error {
w, err := os.Create(dst)
if err != nil {
return err
}
defer w.Close()
f, err := os.Open(src)
if err != nil {
return err
}
defer f.Close()
gr, err := gzip.NewReader(f)
if err != nil {
return err
}
return DecompressSparseReader(gr, *w)
}
高速化
現状は、golang の標準ライブラリの gzip.Reader を利用しているのですが、こいつが解凍後の size を private な変数にしているため、ちょっと面倒な実装になってます。gzip.Readerの実装を見ると簡単そうなので、ここら辺を作り直すとより早くできるかも...? という印象でした。
また、いまだに os.File に対する Write の lock についてよくわかってないので、誰か教えてください。
最後に
スパースなファイルについて検証しているときに 「はー謎」ってなっていたことがあったのですが、 SNS (ソーシャルネットワークサービス)という文明の力を使ったところ一瞬で解決しました。
ええ、天才じゃん
— masahiro331 (@kumagami331) June 18, 2023
ていう話を追記しているときに、さらに知恵が舞い込んできたので、すごいなーっと思いました。
https://t.co/4IqIMyVfCv 使うと semaphore いらないかも
— おりさの (@orisano) 2023年6月19日
XFSを解析した話 (3) - Directory 編
目次
想定読者
XFS Filesystem の生データを解析したいと思っている方に向けた記事です。
- XFSを解析した話 (1) SuperBlock 編
- XFSを解析した話 (2) inode 編
- XFSを解析した話 (3) Directory 編 ← 本記事
- XFSを解析した話 (4) RegularFile 編
今回の記事では、XFSの ディレクトリの inode について解説していきます。
おさらい
XFSの inode は inode core と data fork と attribute fork の3つのデータからなります。

inode core 内の format と mode を元に data fork をパースすることで、その inode に紐づかれた情報を読み取ることが可能です。ディレクトリの場合は、ディレクトリの配下に存在する inode の情報で ファイルの場合は実際のデータが取得できます。
data fork の解析
ディレクトリの format は以下の3種類存在し、それぞれの format に応じて data fork をパースします。
- local
- extents
- btree
この3つの format の違いは data fork で表現できるデータ量が異なります。 local < extents < btree の順番に表現できるデータ量が増加し、 local format では管理しきれなくなると、 extents format に変換されるという形です。また、 data fork のサイズは attribute fork のサイズによって決定されます。(仕様書: 16.3 Data Fork を参照)
attribute fork について
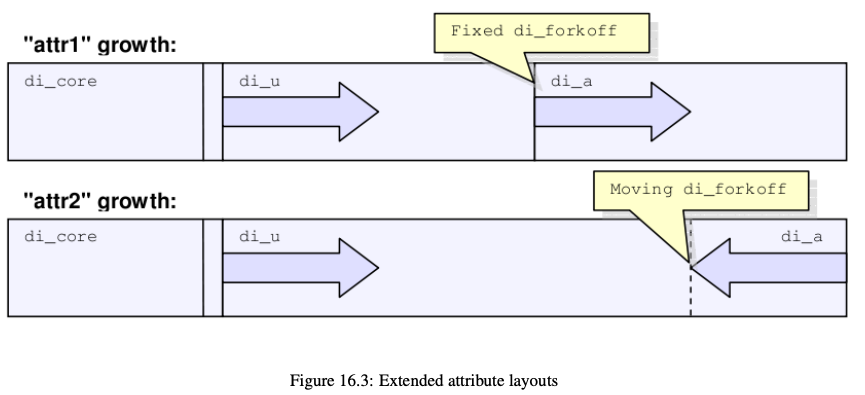
attribute fork は attr1 と attr2 の2種類のバージョンが存在します。違いとしては、inode 内での attribute fork のサイズが固定長か可変長の違いです。 XFSのスーパーブロック内にある features2 パラメータに XFS_SB_VERSION2_ATTR2BIT(0x80)が立っていれば attr2 ということになります。(仕様書: 16.4 Attribute Fork を参照)
実際に確認しましょう。
$ xfs_db xfs.img xfs_db> sb xfs_db> p 色々割愛... features2 = 0x18a
0x18a とでました。 ATTR2BIT は 0x80 なので xfs.img の attribute fork は attr2 のバージョンを利用していることがわかります。attribute fork のサイズは inode core 内にある forkoff によって決定されます。
次に各 format 毎に data fork をパースしていきます。
format local を解析
XFSを解析した話(SuperBlock 編)デバッグ用のイメージを作成 こちらで作成したイメージを利用します。
ルートディレクトリが format local の ディレクトリであるため、初めは root inode の data fork を解析していきます。 rootino のオフセットは root inode の offset を計算 で計算した値を利用します。
改めて root inode のデータを見ましょう。
$ xxd -s 65536 -l 512 xfs.img 00010000: 494e 41ed 0301 0000 0000 0000 0000 0000 INA............. 00010010: 0000 0004 0000 0000 0000 0000 0000 0000 ................ 00010020: 6350 1d2e 04e4 de45 6350 1a4b 0ddb 729e cP.....EcP.K..r. 00010030: 6350 1a4b 0ddb 729e 0000 0000 0000 001c cP.K..r......... 00010040: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00010050: 0000 0002 0000 0000 0000 0000 0000 0000 ................ 00010060: ffff ffff 6af2 441d 0000 0000 0000 0006 ....j.D......... 00010070: 0000 0001 0000 0030 0000 0000 0000 0000 .......0........ 00010080: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00010090: 6350 1834 2a46 72e0 0000 0000 0000 0080 cP.4*Fr......... 000100a0: 1b1b cec8 c7eb 4ff3 bfd5 1fad cd95 ee46 ......O........F 000100b0: 0200 0000 0080 0300 6065 7463 0200 0000 ........`etc.... 000100c0: 8303 0070 7661 7202 0001 2b40 0000 0000 ...pvar...+@.... 000100d0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 以下 0x00 のため省略
inode core のサイズは inode バージョンが 3 の場合 176 で固定のため、 0xb0 からのデータが data fork になります。
これが data fork のデータになります。
000100b0: 0200 0000 0080 0300 6065 7463 0200 0000 ........`etc.... 000100c0: 8303 0070 7661 7202 0001 2b40 0000 0000 ...pvar...+@....
format local の data fork は Short Form Directories と呼ばれ、inode 内に配下ディレクトリの情報が入っています。(仕様書: 18.1 Short Form Directories を参照)

これが実際の構造体になります。
typedef struct xfs_dir2_sf_hdr {
uint8_t count;
uint8_t i8count;
xfs_dir2_inou_t parent; // 4 bytes
} __packed xfs_dir2_sf_hdr_t;
typedef struct xfs_dir2_sf_entry {
__uint8_t namelen;
xfs_dir2_sf_off_t offset; // 2 bytes
__uint8_t name[1];
__uint8_t ftype;
xfs_dir2_inou_t inumber;
} xfs_dir2_sf_entry_t;
ヘッダーに entry 数などが記載され、続く entry のリストにディレクトリの情報が記載されます。 ということで data fork のバイナリを分解しましょう。
000100b0: 0200 0000 0080 0300 6065 7463 0200 0000 ........`etc.... 000100c0: 8303 0070 7661 7202 0001 2b40 0000 0000 ...pvar...+@.... これを分解していく xfs_dir2_sf_hdr 02 - count この後続く entryの数 00 - i8count entry内にいくつ 8 bytes inode が存在するか(よくわかってない) 0000 0080 - parent この inode の親の番号 xfs_dir2_sf_entry[0] 03 - namelen ディレクトリ名の長さ 00 60 - offset わからない... 65 74 63 - name 0x65, 0x74, 0x63 は etc ですね 02 - ftype わからない... 00 00 00 83 - inode の番号(131) xfs_dir2_sf_entry[1] 03 - namelen ディレクトリ名の長さ 00 70 - offset わからない... 76 61 72 - name 0x76, 0x61, 0x72 は var ですね 02 - ftype わからない... 00 01 2b 40 - inode の番号 (76608)
xfs_db で確認してみましょう。
xfs_db> inode 128 xfs_db> p 長いので省略 u3.sfdir3.hdr.count = 2 u3.sfdir3.hdr.i8count = 0 u3.sfdir3.hdr.parent.i4 = 128 u3.sfdir3.list[0].namelen = 3 u3.sfdir3.list[0].offset = 0x60 u3.sfdir3.list[0].name = "etc" u3.sfdir3.list[0].inumber.i4 = 131 u3.sfdir3.list[0].filetype = 2 u3.sfdir3.list[1].namelen = 3 u3.sfdir3.list[1].offset = 0x70 u3.sfdir3.list[1].name = "var" u3.sfdir3.list[1].inumber.i4 = 76608 u3.sfdir3.list[1].filetype = 2
しっかりと計算したものと一致していることがわかります。 これで format local は終わりです。次に format extents について解析します。
format extents を解析
format extents は format local とは異なり、extents という形でデータを管理します。 イメージとしては以下の画像のようなもので、実際のデータに対する pointer を inode 内で保持するような仕組みです。(17.1 Extent List を参照)

format extents を解析するためには、まず format extents の inode を作る必要があるので、作っていきます。作り方は簡単で format local は inode のサイズ 512 bytes から inode core の 172 bytes を引いた 340 bytes のデータしか表現できません。(attribute fork が 0 の場合)そのため 340 bytes 以上のデータを持つような ディレクトリを作成すれば format local は format extents に昇格することがわかります。
最初に作った Linux.img をマウントしてデータを書き込んでいきます。
$ losetup -f # loop5 が空いている場合 $ losetup /dev/loop5 Linux.img $ mount /dev/loop5p2 /mnt/xfs # 適当に長い名前のファイルを3つ作る(128文字を3つにした) $ touch /mnt/xfs/AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA $ touch /mnt/xfs/AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAB $ touch /mnt/xfs/AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAC # xfs.img を取り出す $ xxd /dev/loop5p2 | xxd -r >> xfs.img
xfs.img を xfs_db で確認します。
xfs_db> inode 128 xfs_db> p 長いのでいろいろ割愛 core.nblocks = 1 core.nextents = 1 core.forkoff = 0 core.format = 2 (extents) u3.bmx[0] = [startoff,startblock,blockcount,extentflag] 0:[0,15,1,0]
format extents ですね。xxd を用いて生のデータを見ましょう。
$ xxd -s 65536 -l 512 xfs.img 00010000: 494e 41ed 0302 0000 0000 0000 0000 0000 INA............. 00010010: 0000 0004 0000 0000 0000 0000 0000 0000 ................ 00010020: 63a4 9e1f 07da 00ee 63a4 9e00 2a10 9dd1 c.......c...*... 00010030: 63a4 9e00 2a10 9dd1 0000 0000 0000 1000 c...*........... 00010040: 0000 0000 0000 0001 0000 0000 0000 0001 ................ 00010050: 0000 0002 0000 0000 0000 0000 0000 0000 ................ 00010060: ffff ffff 21fa fe60 0000 0000 0000 000a ....!..`........ 00010070: 0000 0001 0000 0054 0000 0000 0000 0000 .......T........ 00010080: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00010090: 6350 1834 2a46 72e0 0000 0000 0000 0080 cP.4*Fr......... 000100a0: 1b1b cec8 c7eb 4ff3 bfd5 1fad cd95 ee46 ......O........F 000100b0: 0000 0000 0000 0000 0000 0000 01e0 0001 ................ 000100c0: 8303 0070 7661 7202 0001 2b40 8000 8041 ...pvar...+@...A 000100d0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 000100e0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 000100f0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010100: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010110: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010120: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010130: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010140: 4141 4141 4141 4141 4141 4141 4141 4101 AAAAAAAAAAAAAAA. 00010150: 0000 0085 8001 1041 4141 4141 4141 4141 .......AAAAAAAAA 00010160: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010170: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010180: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 00010190: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 000101a0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 000101b0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 000101c0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 000101d0: 4141 4141 4141 4201 0000 0087 0000 0000 AAAAAAB......... 000101e0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000101f0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
あれ... 思ってたのと違う。となった皆様は多いんじゃないでしょうか。
format extents は データ に対する pointer を持つから inode 内にディレクトリの情報などは持たないんじゃないか?というか3つファイルを作成したのに 2つしかなさそうDA☆ となります。
これはファイルシステムあるあるですが、古いデータが残っているだけで実際には使われないゴミデータが残っているという状況です。0x100b0の行を見てもらえればわかりやすいですが、format local の時とは異なるデータが入っています。
format extents の場合、 inode core に続く data fork には extent list というデータが入ります。inode core 内の nextents がいくつの extent を持っているかを表現しています。今回の場合は nextents が 1 のため一つの extents を持つ inode であることがわかります。
では、extents をパースしていきます。このデータは xfs_bmbt_rec と呼ばれるデータで Linux上のコードだと以下のように表現されています。
typedef struct xfs_bmbt_rec {
__be64 l0, l1;
} xfs_bmbt_rec_t;
L0 と L1 という 8 bytes のデータを持つ計 16 bytes の構造体です。
この bmbt_rec を以下の処理で変換してやることで extent のデータが取得できます。

pythonの書き方わかんなくなったので go で変換します。
# 元となるデータ(16 bytes)
# 000100b0: 0000 0000 0000 0000 0000 0000 01e0 0001
func main() {
BmbtRec{L0: 0x00, L1: 0x01e00001}.Unpack()
}
type BmbtRec struct {
L0, L1 uint64
}
func (b BmbtRec) Unpack() {
const BMBT_EXNTFLAG_BITLEN = 1
fmt.Println("StartOff:", (b.L0&Mask64Lo(64-BMBT_EXNTFLAG_BITLEN))>>9)
fmt.Println("StartBlock:", ((b.L0&Mask64Lo(9))<<43)|(b.L1>>21))
fmt.Println("BlockCount:", b.L1&Mask64Lo(21))
}
func Mask64Lo(n int64) uint64 {
return (1 << n) - 1
}
実行結果は以下になります。
StartOff: 0 StartBlock: 15 BlockCount: 1
StartOff は複数の extent を取得した際(今回は 1件だけだが)にどの extent が何番目かを管理する。要は extent list のソート用のデータです。
StartBlock はその extent がファイルシステム上のどの位置に存在するかを示しています。
BlockCount は StartBlock から何ブロック続いているかを示します。
これらの情報を元に format extents な root inode を読み込んでいきます。
今回に関しては、StartOffとBlockCountはともにそこまで意識することはないです。問題は StartBlock です。脳死で BlockSize(4096) * StartBlock なんて計算をすると痛い目に遭います。
解説を書くのが辛くなってきたので、ソースコード貼ります。 go-xfs-filesystem/xfs/sb.go at main · masahiro331/go-xfs-filesystem · GitHub
問題は AG0 ではない AG に extent は存在する場合、単純な計算ではずれるという問題があります。 今回は AG0 のはずなので 15 になると思いますが、一応計算のコードを貼っておきます。
func mask64Lo(n int) int {
return (1 << n) - 1
}
func main() {
const (
Agblocks = 4862
Agblklog = 13
StartBlock = 15
)
AgBlockNumber := StartBlock & mask64Lo(Agblklog)
AgNumber := StartBlock >> Agblklog
fmt.Println(AgNumber*Agblocks + AgBlockNumber)
}
ということで xxd を用いて 4096 * 15 に飛んで 1ブロック分だけデータを取得します。
$ xxd -s 61440 -l 4096 xfs.img 0000f000: 5844 4233 a065 f0a0 0000 0000 0000 0078 XDB3.e.........x 0000f010: 0000 0001 0000 004d 1b1b cec8 c7eb 4ff3 .......M......O. 0000f020: bfd5 1fad cd95 ee46 0000 0000 0000 0080 .......F........ 0000f030: 0230 0d90 0000 0000 0000 0000 0000 0000 .0.............. 0000f040: 0000 0000 0000 0080 012e 0200 0000 0040 ...............@ 0000f050: 0000 0000 0000 0080 022e 2e02 0000 0050 ...............P 0000f060: 0000 0000 0000 0083 0365 7463 0200 0060 .........etc...` 0000f070: 0000 0000 0001 2b40 0376 6172 0200 0070 ......+@.var...p 0000f080: 0000 0000 0000 0085 8041 4141 4141 4141 .........AAAAAAA 0000f090: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f0a0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f0b0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f0c0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f0d0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f0e0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f0f0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f100: 4141 4141 4141 4141 4101 0000 0000 0080 AAAAAAAAA....... 0000f110: 0000 0000 0000 0087 8041 4141 4141 4141 .........AAAAAAA 0000f120: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f130: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f140: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f150: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f160: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f170: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f180: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f190: 4141 4141 4141 4141 4201 0000 0000 0110 AAAAAAAAB....... 0000f1a0: 0000 0000 0000 0088 8041 4141 4141 4141 .........AAAAAAA 0000f1b0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f1c0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f1d0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f1e0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f1f0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f200: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f210: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA 0000f220: 4141 4141 4141 4141 4301 0000 0000 01a0 AAAAAAAAC....... 0000f230: ffff 0d90 0000 0000 0000 0000 0000 0000 ................ 長いので割愛
しっかり取れていますね。 先頭のマジックバイトに注目すると、XDB3と表示されていることがわかります。
![]()
これは format extents の中でも Block Directories と呼ばれる形式になります。Block Directories は extent の先に format local のような形でディレクトリの情報が入っているタイプになります。
このようなイメージです。

ということで、データをパースしていきます。
struct xfs_dir3_blk_hdr {
__be32 magic; /* magic number */
__be32 crc; /* CRC of block */
__be64 blkno; /* first block of the buffer */
__be64 lsn; /* sequence number of last write */
uuid_t uuid; /* filesystem we belong to */
__be64 owner; /* inode that owns the block */
};
struct xfs_dir3_data_hdr {
struct xfs_dir3_blk_hdr hdr;
xfs_dir2_data_free_t best_free[XFS_DIR2_DATA_FD_COUNT];
__be32 pad; /* 64 bit alignment */
};
はじめにヘッダー部分を実装を参考にパースしていきます。
# 元となるデータ 0000f000: 5844 4233 a065 f0a0 0000 0000 0000 0078 XDB3.e.........x 0000f010: 0000 0001 0000 004d 1b1b cec8 c7eb 4ff3 .......M......O. 0000f020: bfd5 1fad cd95 ee46 0000 0000 0000 0080 .......F........ 0000f030: 0230 0d90 0000 0000 0000 0000 0000 0000 .0.............. xfs_dir3_blk_hdr 5844 4233 magic マジックバイト a065 f0a0 crc 誤りの検出用 0000 0000 0000 0078 blkno 実データが入ってるブロック 0000 0001 0000 004d lsn ログ用のやつらしい 1b1b cec8 c7eb 4ff3 bfd5 1fad cd95 ee46 uuid UUID 0000 0000 0000 0080 このextentを持つinodeの番号 xfs_dir2_data_free_t // XFS_DIR2_DATA_FD_COUNT = 3 0230 0d90 best_free[0] 使ってないのでわかりません() 0000 0000 best_free[1] 0000 0000 best_free[2] padding 0000 0000 アライメント用です
あとは local extent と同様に block を追いかけることでパース可能です。
今日の記事では割愛しますが、 format extents にはこの他にも Node Directories, Leaf Directories などさらに階層化が可能な仕組みが存在します。またそれらでも表現できなければ、 format btree が登場します。
XFSを解析した話 (2) - inode 編
目次
想定読者
XFS Filesystem の生データを解析したいと思っている方に向けた記事です。
- XFSを解析した話 (1) SuperBlock 編
- XFSを解析した話 (2) inode 編 ← 本記事
- XFSを解析した話 (3) Directory 編
- XFSを解析した話 (4) RegularFile 編
今回の記事では、前回作成した XFS のバイナリデータを用いて、XFSの inode について触れていきたいと思います。
はじめに
前回も少し説明しましたが、inode は Linux 上のファイル に一意に付与される番号です。つまりファイルシステムに管理できるファイルは、inode の総数に依存します。
ファイルの種類は以下の7つになります。
- Regular file
- Directory
- Character special device
- Block special device
- FIFO
- Socket
- Symlink
XFS ではファイルの inode と実際のデータは別で管理されているため、inode にはデータが保存されている場所が保存されています。
その他にも、ファイルの所有者やタイムスタンプの情報などが格納されています。
今回は XFS 上に存在する inode の探索方法と、inode の作りについて解説していこうと思います。 前回の記事で作成したイメージを使って解説します。
XFSを解析した話(SuperBlock 編)デバッグ用のイメージを作成
また、XFSの inode は version 1,2 と 3 で異なります。本記事では version 3 を前提として解説します。
inode について
XFSの inode について説明します。仕様書 の Chapter 16 On-disk Inode に詳細が記載されているのでそれらをもとに解説します。
XFSの inode は以下の3つの構造体からなります。
- inode core
- data fork
- extended attribute fork
inode core には file stat の情報と、data fork, extended attribute fork に記載されるデータの種別を保持しています。
data fork には inode に関連するデータ(通常のファイルやディレクトリなど)へ参照するための情報が入っています。
extended attribute fork には inode に対するメタデータが含まれます。実は自分もあまりわかっておらず、SELinuxなどの機構を入れるための場所なのかなというイメージです。
inode の解析
任意の inode を解析するにあたって、まずは root inode を取得する必要があります。
ファイルシステム上の任意のディレクトリに行くにしても必ずルートディレクトリから辿るように(絶対パスの場合)ファイルシステムを探索する際も root inode(ルートディレクトリの inode)をみる必要があります。
任意の inode の情報をバイナリ上で取得するのに必要なのは inode 番号です。 root inode の番号はスーパーブロックに記載されています。
root inode 番号の調査
xfs_db を用いて root inode 番号を探しましょう。
# xfs.img は、前回記事で作ったものです。 $ xfs_db xfs.img xfs_db> sb xfs_db> p ... 色々割愛 rootino = 128
rootino を見ることで、このXFSの root inode 番号は 128 であることがわかります。
ちなみに xfs_db なんて使わねえ!という方向けにバイナリから探す方法だと、下記のコードを参考にスーパーブロックのデータから rootino を探すことも可能です。
構造体を見るとスーパブロックの 56 bytes から 8 bytes が rootino であることがわかるため、下記のようにすることで rootino の値が取得できます。
$ xxd -s 56 -l 8 xfs.img 00000038: 0000 0000 0000 0080 ........
このように 0x80 なので 128 で rootino が 128 であることが確認できます。
次に root inode のデータがバイナリ上のどこに配置されているかを計算します。
root inode の offset を計算
XFS の inode 番号は2つの形式を持っており、AG相対番号と絶対番号を持ってます。
AG相対番号は 4 bytes で表現できるよう設計されており、絶対番号は 8 bytes で表現できるよう設計されています。
AGFやAGI(確保済みの inode や空いている inode を保持している)ではAG相対番号を利用していますが、root inode や あるディレクトリが持っている inode 番号などは絶対番号です。詳細が気になる方は仕様書の(13.3 AG Inode Management)を確認してください。
本記事では 絶対番号 (以下 inode 番号) を利用して解説します。
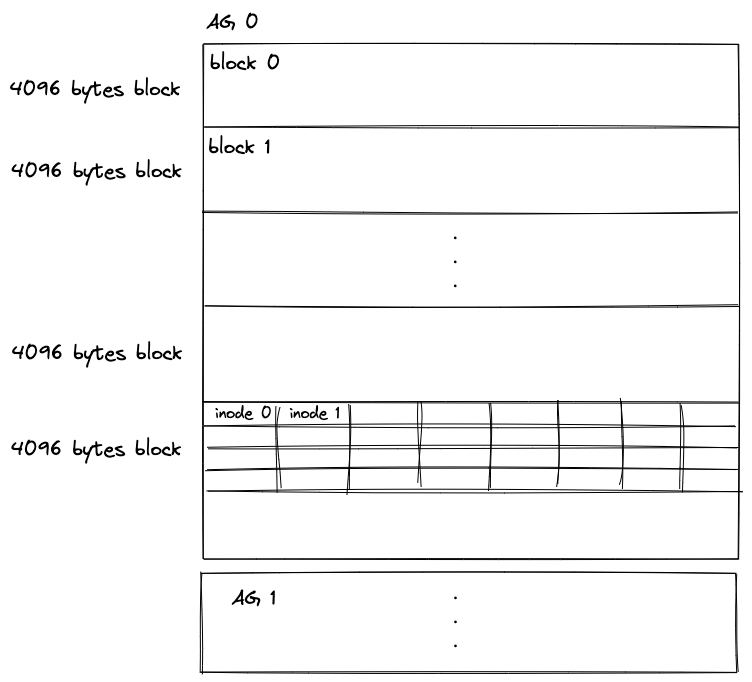
inode 番号は以下の図のように3つの要素を含んでおり、スーパーブロックに記載されている bit 長をもとに分解できます。
- AG number
- Block number
- inode position

AG number はその inode がどの AG に配置されているかを示しています。
Block number はその AG 内の何ブロック目かを示しています。
inode position はそのブロックの何番目かを示しています。
イメージとしてはこんな感じです。
ということで計算していきましょう。 root inode は128と小さな数字なので簡単です。 はじめに必要な情報をスーパーブロックから取得しましょう。
$ xfs_db xfs.img xfs_db> sb xfs_db> p いろいろ割愛 blocksize = 4096 agblocks = 4862 inodesize = 512 inopblock = 8 inopblog = 3 agblklog = 13
※ inopblock は 1 blockあたりの inode 数です。 blocksize / inodesize でも計算できますが、スーパーブロックに入ってるので利用します。
※ agblocks は AG あたりの block 数です。
はじめに inode 番号から AG number, Block number, inode positionを計算します。
bit計算などをするので pythonを使います。
inode_number = 128 inopblog = 3 agblklog = 13 inopblock = 8 ag_musk = inopblog + agblklog low_musk = (1 << ag_musk) - 1 ag_number = inode_number >> ag_musk block_number = (inode_number & low_musk) / inopblock inode_position = (inode_number & low_musk) % inopblock
ここまでで、どこのAGの何ブロック目の何番目に root inode が入っていることがわかります。 あとはこれらの情報をもとに offset を計算します。
blocksize = 4096 agblocks = 4862 inodesize = 512 # AGのサイズを計算 ag_size = agblocks * blocksize # オフセットを計算 inode_offset = (ag_size * ag_number ) + (block_number * blocksize) + (inode_position * inodesize)
これらを計算すると、 inode の offset は 65536 であることがわかります。(みんな気がつくと思いますが、あまり面白くない inode 番号)
root inode を解析
先ほどまでで、 root inode の offset を計算したので、実際に見てみましょう。
$ xxd -s 65536 -l 512 xfs.img
00010000: 494e 41ed 0301 0000 0000 0000 0000 0000 INA.............
00010010: 0000 0004 0000 0000 0000 0000 0000 0000 ................
00010020: 6350 1d2e 04e4 de45 6350 1a4b 0ddb 729e cP.....EcP.K..r.
00010030: 6350 1a4b 0ddb 729e 0000 0000 0000 001c cP.K..r.........
00010040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00010050: 0000 0002 0000 0000 0000 0000 0000 0000 ................
00010060: ffff ffff 6af2 441d 0000 0000 0000 0006 ....j.D.........
00010070: 0000 0001 0000 0030 0000 0000 0000 0000 .......0........
00010080: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00010090: 6350 1834 2a46 72e0 0000 0000 0000 0080 cP.4*Fr.........
000100a0: 1b1b cec8 c7eb 4ff3 bfd5 1fad cd95 ee46 ......O........F
000100b0: 0200 0000 0080 0300 6065 7463 0200 0000 ........`etc....
000100c0: 8303 0070 7661 7202 0001 2b40 0000 0000 ...pvar...+@....
000100d0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
... 全部 0x00 なので割愛
000101f0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
inode のマジックバイトが IN(0x494e) なのであってそうです。仕様書の(16.1 Inode Core)を参考にするとバイナリのまま読むことができますが、xfs_dbでも確認できるので今回はそちらでみます。
$ xfs_db xfs.img xfs_db> inode 128 xfs_db> p core.magic = 0x494e core.mode = 040755 core.version = 3 core.format = 1 (local) かなりでたと思いますが、一旦割愛
重要なのは verision と mode と format です。 version は 3 であることを確認してください。(本記事は 1, 2 が対象外なので 3 以外が出たら困る)
次に mode です。これは linux の file mode です。普段目にするのは permission の 755 の部分だけかと思いますが、今回は 40000 がついています。man コマンドで inode の詳細が検索できるのでみましょう。
$ man 7 inode
... 割愛
The file type and mode
The stat.st_mode field (for statx(2), the statx.stx_mode field) contains the file type and mode.
POSIX refers to the stat.st_mode bits corresponding to the mask S_IFMT (see below) as the file type, the 12 bits corresponding to
the mask 07777 as the file mode bits and the least significant 9 bits (0777) as the file permission bits.
The following mask values are defined for the file type:
S_IFMT 0170000 bit mask for the file type bit field
S_IFSOCK 0140000 socket
S_IFLNK 0120000 symbolic link
S_IFREG 0100000 regular file
S_IFBLK 0060000 block device
S_IFDIR 0040000 directory
S_IFCHR 0020000 character device
S_IFIFO 0010000 FIFO
...
man コマンドでこの様な文章を読むことが可能です。 S_IFDIR に書いてある通り、0040000 は directory のようです。
最後に format ですが、これは inode に紐づく data fork のフォーマットのことです。この inode はディレクトリでその詳細は format 1(local)で表現されていることがわかります。
format は以下の種類が存在します。
- XFS_DINODE_FMT_DEV
- XFS_DINODE_FMT_LOCAL
- XFS_DINODE_FMT_EXTENTS
- XFS_DINODE_FMT_BTREE
- XFS_DINODE_FMT_UUID
- XFS_DINODE_FMT_RMAP
詳細は(16.1 Inode Core)に記載されています。 主に利用されているのは、dev, local, extents, bree の 4つです。詳細は後述します。
ファイルには複数の type が存在しますが、regular file(通常のファイル)と directory だけでも以下の組み合わせが存在します。
- local × directory
- extents × directory
- btree × directory
- extents × regular file
- btree × regular file
詳細は(仕様書: 16.3 Data Fork)に記載されています。
これらの組み合わせで data fork をパースすることで、directory であれば配下ディレクトリのデータを取得できたり、regular file であれば実際のデータを取得することが可能です。
おわり
今回の記事はここまでとして、次の記事で data fork について記載しようと思います。 おそらく、regular file編 と directory編に分けると思います。
XFSを解析した話 (1) - SuperBlock 編
はじめに
XFS ファイルシステムを解析できるGolangのライブラリを作りました。
Trivyというコンテナ脆弱性検知ツールで仮想マシンイメージの脆弱性検知機能を開発するにあたって、KernelやC言語の資源に依存せずにXFSを解析する必要がありました。
仕事終わりの時間を使ってガッと作ったので対応していないデータ構造などもありますが、一旦動くものができたので、知識を貯めるという意味でも記事に残そうと思います。
かなり長い記事になりそうなので、何回かに分けて記事を作成しようと思います。
目次
想定読者
XFS Filesystemの生データを解析したいと思っている方に向けた記事です。
- XFSを解析した話 (1) SuperBlock 編 ← 本記事
- XFSを解析した話 (2) inode 編
- XFSを解析した話 (3) Directory 編
- XFSを解析した話 (4) RegularFile 編
今回の記事では、XFSのバイナリデータを作成して、スーパーブロックのデータを見たいと思います
作ったライブラリ
Goの io/fs の FS interfaceに合わせて実装していますので、簡単に利用できるかと思います。
作ったもの
GitHub - masahiro331/go-xfs-filesystem
io/fsのドキュメント
fs package - io/fs - Go Packages
概要
ではXFSの解析に必要な知識をまとめていきます。
今回の記事では以下のような点は記載しておりません。
- Journal Log
- Extended Attributes
- ファイルの書き込み, 削除など
Extended Attributesはファイルに紐づくメタ情報のようなもので、SELinuxなどの情報が入っています。(知らんけど)
初めに
まずは公式ドキュメントと信頼できる解析ツールを用意しましょう。
公式のドキュメントは以下のようにビルドするか、古いですがインターネットに公開されているやつを見ましょう。
$ git clone git://git.kernel.org/pub/scm/fs/xfs/xfs-documentation.git $ cd xfs-documentation $ make
僕は centos:7 ですが、別になんでもいいです。
$ yum install xfs_dumps
(前提知識の補足)ファイルシステムの構造について
私はXFSとEXT4のデータ構造しか知らないのですが、ファイルシステムには以下のような共通のデータ構造があります。
- SuperBlock
- Inode
- Extents List (Tree)
Superblock とは
ファイルシステムがHDDのデータを管理するためのサイズをブロックと呼び、ブロックのサイズはSuperBlockに書かれています。
そのためファイルシステムの先頭にSuperBlockが配置されていることが多いです。
(※ EXT4では先頭1024バイトにBootSectorが配置されていることがあるため、1024バイト目から SuperBlockが始まります。 )
SuperBlockにはファイルシステムを読み込むために必要な情報が書かれており、例えばInodeあたりのサイズやファイルシステム全体のブロック数などが管理されています。
参考: スーパーブロック (ファイルシステム) - Wikipedia
Wikipediaが詳しいです。
Inode とは
InodeはLinux上のファイル に一意に付与される番号です。つまりファイルシステムに管理できるファイルは、Inodeの総数に依存します。
ファイルの種類
- Regular file
- Directory
- Character special device
- Block special device
- FIFO
- Socket
- Symlink
Linux上ではファイルのInodeと実際のデータは別で管理されているため、Inodeにはデータが保存されている場所が保存されています。
その他にも、ファイルの所有者やタイムスタンプの情報などが格納されています。
参考: inode - Wikipedia
Wikipediaを信じましょう。
Extents Listとは
Extents List(Tree) はよくわかってないです。 僕の認識ではInodeとデータを紐づける中間データをExtents Listと呼んでおり、実データの領域をExtentsと呼んでいる気がします。
参考: Extent (file systems) - Wikipedia
これもWikipediaを信じましょう。
XFSについて
共通の用語がわかったところでXFSについて記載していきます。
XFSではファイルシステムを Allocation Group(以降はAGと記載) と呼ばれる単位で分割して管理しています。
各AGは独立して、空き容量やinode、その他のメタデータを管理しているため、個別のファイルシステムとほぼ見なすことができます。
これにより、同時アクセスの数が増えてもパフォーマンスを低下させることなく、XFSでの操作を並行することが処理できます。
AGについて
AGの最大サイズは 1TBであり、AGあたりのサイズはSuperBlockのAgBlocksとBlockSizeの積によって求められます。
ファイルシステム内のAGの個数はSuperBlockのAgCountで管理されています。
AGは物理的に連続に配置されているため、N番目のAGの開始位置は AgBlocks * BlockSize* N で表現されます 。
各AGの先頭 block には以下の4つのデータが管理されており、各データが512バイトごとに配置されています。
- SuperBlock
- AGF
- AGFL
- AGI
SuperBlockについて
各AGは、スーパーブロックから始まり、最初の AG に属する SuperBlock は Primary SuperBlock と呼ばれ、基本的にはこの SuperBlock を参照してファイルシステムを読み込んでいきます。 以降の AG に存在する SuperBlock は Secondary SuperBlock と呼ばれ Primary SuperBlock が破損した際のバックアップとして用いられます。
SuperBlock の実装は以下のコードに記載されています。
AGF について
AGFは AG Free Space と呼ばれ、 AG内の空き領域を追跡するための領域です。
2つの B+Tree を使用してAG内の空き領域を管理し、1つは B+Tree でブロック番号を指し、もう1つの B+Tree で空き領域ブロックのサイズを記録します。 注意点としてブロック番号などの値は、AGのブロックオフセットからの相対値です。
今回の実装では完全に無視しています。
AGFL について
AGFLは AGフリーリスト と呼ばれ、AG Free Space の B+Tree が大きくなった場合に利用される、予約済みスペースです。 AGFL で管理されるブロックスペースは inodeやデータなどでは利用できないようになってます。
今回の実装では完全に無視しています。
AGI について
AGI は AG内の Inode を管理します。 AG内で使用している inode数や B+Tree のレベル制限などが記載されています。
今回の実装では完全に無視しています。
実際のデータに触れてみる
簡単なXFSのデータを以下の手順で作成して触ってみましょう。
デバッグ用のイメージを作成
# はじめにからのブロックデバイスを作成します。 $ dd of=Linux.img count=0 seek=1 bs=41943040 # 空いているループデバイスを検索 $ losetup -f # 出力されたループデバイスと先ほど作成したブロックデバイスを接続(/dev/loop5が出力された場合) $ losetup /dev/loop5 Linux.img # パーティションを作成していきます。 # 先頭 1MiB から 2MiB までをbootパーティションとして作成 # 先頭 2MiB から 最後までを XFSのパーティションとして作成 $ parted /dev/loop5 (parted)$ mklabel gpt (parted)$ mkpart primary 1MiB 2MiB (parted)$ set 1 boot on (parted)$ mkpart primary xfs 2MiB 100% (parted)$ quit # XFS ファイルシステムで先ほど作った XFSパーティションをフォーマット # loop5 の partition 2という意味で loop5p2 という表現になっていると推測(知らん) $ mkfs.xfs /dev/loop5p2 # xfsのパーティションを /mnt/xfs にマウント $ mount /dev/loop5p2 /mnt/xfs # ファイルとかが作成できることを確認 $ mkdir /mnt/xfs/etc/ $ cp system-release /mnt/xfs/etc/system-release # アンマウント $ umount /mnt/xfs # ループデバイスとの接続を切断 $ losetup -d /dev/loop5
これで作成した Linux.img はブートパーティション付きのXFSファイルシステムが入ったイメージになりました。パーティションなど作成せずにイメージを作成できるかもしれませんが、自分は知らないので知っている方は教えてください。
次は作成したデータを見てみましょう。
スーパーブロックを眺める
# 先頭 2MiB から 512 bytes 分だけ出力
$ xxd -s 0x200000 -l 0x200 Linux.img
00200000: 5846 5342 0000 1000 0000 0000 0000 25fb XFSB..........%.
00200010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00200020: 1b1b cec8 c7eb 4ff3 bfd5 1fad cd95 ee46 ......O........F
00200030: 0000 0000 0000 2006 0000 0000 0000 0080 ...... .........
00200040: 0000 0000 0000 0081 0000 0000 0000 0082 ................
00200050: 0000 0001 0000 12fe 0000 0002 0000 0000 ................
00200060: 0000 0558 b4a5 0200 0200 0008 0000 0000 ...X............
00200070: 0000 0000 0000 0000 0c09 0903 0d00 0019 ................
00200080: 0000 0000 0000 0080 0000 0000 0000 0077 ...............w
00200090: 0000 0000 0000 1bb6 0000 0000 0000 0000 ................
002000a0: ffff ffff ffff ffff ffff ffff ffff ffff ................
002000b0: 0000 0000 0000 0008 0000 0000 0000 0000 ................
002000c0: 0000 0000 0000 0001 0000 018a 0000 018a ................
002000d0: 0000 0000 0000 0005 0000 0003 0000 0000 ................
002000e0: 47b4 f325 0000 0004 ffff ffff ffff ffff G..%............
002000f0: 0000 0001 0000 0038 0000 0000 0000 0000 .......8........
... 全部 0x00 なので割愛
002001f0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
先頭4bytes がスーパーブロックのマジックバイトである、XFSB(0x58465342) となっており、正しくとれていそうです。仕様書を眺めながら見ていただいても良いのですが、大変なので xfs_db を使ってもう少しわかりやすくしましょう。
# Linux.imgには boot partitionが存在するため、XFSのデータ領域だけ取ってやる $ xxd -s 0x200000 Linux.img | xxd -r >> xfs.img # xfs_db でデバッグする $ xfs_db xfs.img # インタラクティブなやつが立ち上がるので、以下の手順で確認(helpが使えるので気になる方は調べてください) xfs_db> sb xfs_db> p magicnum = 0x58465342 blocksize = 4096 dblocks = 9723 rblocks = 0 rextents = 0 uuid = 1b1bcec8-c7eb-4ff3-bfd5-1fadcd95ee46 logstart = 8198 rootino = 128 rbmino = 129 rsumino = 130 rextsize = 1 agblocks = 4862 agcount = 2 rbmblocks = 0 logblocks = 1368 versionnum = 0xb4a5 sectsize = 512 inodesize = 512 inopblock = 8 色々長いので割愛 meta_uuid = 00000000-0000-0000-0000-000000000000
いろいろ情報がでてきました。
先ほど説明したこれらが本当かどうか確かめてみましょう。
AGあたりのサイズはSuperBlockのAgBlocksとBlockSizeの積によって求められます。
ファイルシステム内のAGの個数はSuperBlockのAgCountで管理されています。
AGは物理的に連続に配置されているため、N番目のAGの開始位置はAgBlocks * BlockSize* Nで表現されます 。
今回作成したXFSは2つのAGを持っているようです。各AGはスーパーブロックを保持しているので、2つめのAGの先頭 8 bytes は XFSB のマジックバイトを持っているはずです。
agcount = 2 blocksize = 4096 agblocks = 4862
xfs_dbの出力結果をもとに xxd で2つめのAGの先頭バイトを確認しましょう。
# AG Offset = blocksize * agblocks * ag number(0から数えます). # AG Offset = 4096 * 4862 * 1 # AG Offset = 19914752 $ xxd -s 19914752 -l 8 xfs.img 012fe000: 5846 5342 0000 1000 XFSB....
先頭 8 bytes が XFSBになっているため、正しくAGが配置されていることがわかります。
おわり
本記事はここまでにします。
次の記事では inode について深掘りしていこうと思います。 このスーパーブロックはinodeを取得するときなどにも利用するので、今回触れなかったパラメータについては次以降の記事で触れていこうと思います。
仮想マシンイメージの脆弱性検知をTrivyに組み込んだ話
はじめに
2022年11月にOSSのコンテナ脆弱性検知ツール Trivy に 仮想マシンイメージ(VMDKやVDIなど)の脆弱性検知機能を追加しました。
今回はこの機能を追加した苦労話や具体的な技術について解説したいと思います。
技術話を書くと、正直クソ長文章になることは明白なので 誰も読まない&書くのが辛い ということは目に見えてるのですが、備忘録も兼ねて書こうと思います。
以下、追加したPull Requestです。
リリース時の公式ブログ
このブログでのプログラミング用語は基本的にGo言語で説明されます。
実際に作ったもの
Aqua Security が youtube にしてくれているので貼っておきます。
ここから先が長すぎて面倒だという方向け
僕が所属する会社のグループ(課)では毎週交代制で1時間LT(1時間がライトニングなのかはさておき)をするのですが、それで発表した資料を公開しているので載せておきます。
ブログ長くて面倒だって人は以下の資料でサマってるのでそれで思います雰囲気を理解してもらえればと。
OSSに新機能を追加するまでの苦労話 - Speaker Deck
Analyze Filesystem in Virtual Machine Image - Speaker Deck
なぜVMのスキャンが必要なのか?
なぜ必要なのかは、Aquaの中の人がブログ?に書いてたので引用します。
While Trivy is widely popular for scanning container and cloud native workloads, some organisations, and some applications still run on Virtual Machines (VM).
英語が読めないのでDeepLを使いましたが、まだまだVMも世の中には沢山稼働していて、それの検知もしたい!ということらしいです。
全体像
簡単に開発した機能について説明します。 機能についてはTrivyのリリースノートから抜粋します。
v0.35.0 · Discussion #3231 · aquasecurity/trivy · GitHub
Trivy now scans AWS AMI images and EBS snapshots. You just need to specify your AMI ID with the ami: prefix.
はい。実はファーストターゲットは AWS AMI の脆弱性検知をターゲットにしています。理由は世の中に存在する数多あるVMDK等の仮想マシンイメージのスキャンは絶望的だからです。
現時点(Trivy v0.35.0)では安定動作するのは AWS AMIと AWS Instanceを VMDKにExportしたもののみです。 なぜ初期仕様が AWS AMI にフォーカスしているのかも後述で説明しようと思います。
まず始めにTrivyの動作について紹介します。
Trivyの脆弱性検知について
簡単にTrivyの脆弱性検知に対するアプローチを説明すると、Docker Imageやある特定のリポジトリ内に存在する、パッケージ管理システムのファイルを解析することによって脆弱性検知をします。
例えば RedHat系のOSに yumコマンドでインストールされるパッケージの場合、/var/lib/rpm/Packages コマンドを解析することでインストールされているパッケージを取得し、公開されている脆弱性情報とマッチングして検知します。
Rubyのパッケージの場合、gemspecファイルや、Gemfile.lockを解析することで、インストールされているパッケージを取得し、公開されている脆弱性情報とマッチングして検知します。
開発する上での課題
最も大きな課題は、仮想マシンイメージなどを対象とした場合に、解析するにあたっての画一された手法が存在せず、現状仮想マシンイメージを対象としたSCAツールも存在していないことです。 (コピペエンジニアとって、パクる対象がないのは辛いところです)
その他にも以下のような課題がありました。
課題1. 実装が困難
仮想マシンイメージを解析するためには以下のように多層のレイヤーを読み取る必要があります。
Virtual Image → Disk Partition → Filesystem → File
Trivyでは全てのユーザ環境で動作できるよう極力アーキテクチャ依存の実装を避ける方針にあります。 例えば、rpmのパッケージを解析するために rpmdb のパーサをGo言語で書き直す など @knqyf263 の執念を感じる実装が多いです。
そのため、各層の解析にはC言語の資産を使いたくないというモチベーションがありました。(C言語の資産を使っても面倒ですが)
課題2. リソース上の課題
仮想マシンイメージをディスク上に解凍すると 数百MB ~ 数GB から 数十GB ~~ のデータ量になるため、Trivyの実行環境として推奨されている CI/CDパイプラインでの利用が困難になります。
そのため、どうにかして圧縮されている仮想マシンイメージから いい感じ にファイルシステムを解析し必要なファイルを取り出す処理が必要になります。
アーキテクチャ
ざっくり言うと、仮想マシンイメージの中に存在するファイルシステムをパースして、脆弱性検知に必要なファイルを抽出する機能です。
全体のアーキテクチャはこのような感じです。

仮想マシンを以下の6つの層に分解しています。
- Storage層
- Virtual Machine Image層(Virtual Diskが厳密かもしれない)
- Disk Partition層
- Logical Volume層
- Filesystem層
- File層
全体の方針としては、全てのレイヤーを透過的に io.ReadSeeker インターフェースを通じてアクセスできることにしています。 また、全ての実装においてGo言語で書き直すことにしました。
各層について詳細を説明していきます。
Storage層
Storage層はスキャン対象のファイルがどのインフラ上(バックエンド)に展開されているかによって動作を変えるものです。例えばローカルストレージ上にファイルとして展開されている場合は、 io.ReadSeeker インターフェースを満たす os.File 構造体 を利用します。
その他にも、AWS上のEBSにイメージが配置されている場合などを想定した層になります。
現時点でサポートしているのは、EBSとFileになりますが、将来的には、vagrant hub(box) や GCP, Azure のイメージレジストリーなども追加していければという目論見があります。
EBS Storage
まず AWS EBS とはなんぞや!という方が多いと思いますので説明します。
Elastic Block Store の略なのですが、EC2からマウントしたり、EC2のスナップショットを保存したり、AMIのデータが保存されたりするストレージです。
そのため、EBSをサポートすることによって、EC2スナップショットの検知や、AMIの検知が可能となっています。
ローカルストレージ上のファイルを io.ReadSeekerインターフェースを満たすことなど造作もないですが、AWS EBSはどうなのだ!というところが重要です。
この機能のために AWS EBS を io.ReadSeekerできるライブラリを開発しました。
GitHub - masahiro331/go-ebs-file
実装は簡単です。 AWS EBS は EBS Direct API を公開しており、 512KB ごとのブロックをbytesデータとして読み書きできます。
例えば 任意のEC2スナップショットに対してブロックのリストを取得するためには awsコマンドで以下のように取得できます。
$ aws ebs list-snapshot-blocks --snapshot-id snap-0f8fe7914a70eca70
{
"Blocks": [
{
"BlockIndex": 0,
"BlockToken": "**********************"
},
{
"BlockIndex": 1,
"BlockToken": "**********************"
},
{
"BlockIndex": 2,
"BlockToken": "**********************"
},
...
],
"ExpiryTime": "2022-12-24T22:26:26.973000+09:00",
"VolumeSize": 8,
"BlockSize": 524288
}
EBSのボリュームサイズは1GB毎に確保されるため、 VolumeSize: 8 は 8GBのストレージで 1ブロックあたり 512KBのデータを持っているため 8GB / 512KB から 16384 ブロックが存在することが導出されます。
厳密には Amazon Linux Imageのスナップショットの場合、ブロック内の全てのデータが 0x00 の場合は無視できるようにリストから除外されてたりします。
イメージとしてはこんな感じです。

Goの ioパッケージは io.SectionReader という便利なものを提供してくれており、io.ReaderAt と Size() int64 を満たす構造体を io.ReadSeeker を満たすように変換してくれます。
つまり Direct APIを使って、io.ReaderAt と Size() int64 を実装し io.SectionReader を使うことで、インターネット越しに EBS に対して Seek, Read することが可能です。
Virtual Machine Image層
この層はVMDK(VMWare)や VDI(Virtual Box)、 QCOW2(KVM)、VHDX(Hyper visor)など謂わゆる仮想マシンイメージのディスクフォーマットを解析する層になります。各イメージフォーマットに複数のディスクタイプが存在するため正直無限に手が足りません。
現時点でサポートしているのはここら辺です。
基本的なVirtual Diskのアーキテクチャは物理のディスクデータを任意のブロックサイズに分割し、ブロック内のデータが 0x00 で埋まっている場合は除くことで、データを圧縮するようなものになってます。
可逆性を持たせるために、仮想ディスクのブロックが物理ディスク上の何番目のブロックだったかを記録するツリーデータを持たせている実装が多いです。
イメージとしては以下のような感じ

ややこしいのは、実装によっては分割されたブロック毎に Deflateなどを用いてさらに圧縮しているフォーマットも存在します(VMDKのStreamOptimizedフォーマットなど)
実装としては EBSと同様に io.ReaderAt と Size() int64 を実装してやって io.SectionReader で包んでやる方針です。
イメージとしては以下のコードです。
var _ VM = &VMDK{}
type VMDK struct {
f *os.File // 実体のファイルのポインタ
size int
}
type VM interface {
io.ReaderAt
Size() (n int)
}
func (v *VMDK) ReadAt(p []byte, off int64) (n int, err error) {
logicalOffset := v.translateOffset(off)
return v.f.ReadAt(p, logicalOffset)
}
func (v *VMDK) Size() (n int) {
return v.size
}
func (v *VMDK) translateOffset(physicalOffset int64) (logicalOffset int64) {
// 圧縮データに対する物理オフセットから解凍した場合に参照されるオフセットを変換する
// ツリーデータを読み取ってオフセットを変換してあげる
// Deflate圧縮されていたら部分的に解凍した場合のオフセットを返す
return logicalOffset
}
重要なのは translateOffset(physicalOffset int64) int64 関数です。ここで仮想ディスクの物理オフセットを展開した場合の論理オフセットに変換してあげることです。
実際のコード
作ったライブラリ
Disk Partition層
Disk Partition層は Master boot record(MBR)やGUID Partition Table(GPT)を解析する層になります。
例えば、MBRのブートパーティションは無視するなどの処理や、データパーティション1は N byte目から M bytesの領域に配置されているなどの解析がメインの処理です。
イメージとしてはこのようなデータ構造になっています。

必要な実装としては、そのパーティションがどういったタイプなのか?(Swap、Root、Bootなど)と特定パーティションの io.ReadSeeker を 返すだけなので、実質 tarみたいなものだなと言う気持ちで、archive/tar パッケージっぽく使えるように実装しました。
作ったライブラリ
Logical Volume層
Logical Volume層は Logical Volume Manager(LVM)によって作成された、論理ボリュームを解析する層になってます。現時点ではまだサポートしておらず鋭意開発中です。
Vagrant Boxなどで公開されている比較的新しい仮想マシンイメージは大体LVMを使ってるので、これをサポートしないと、野良VMのサポートができましたとは言えません。AMIはLVMを使ってなくて本当に助かりました。
なぜLVMやってないの!?という方向けの言い訳を書くんですが、基本的に仕様書通りにバイナリデータをパースしておけば実装できると思っていましたが、LVMのバイナリデータ内に、Textデータとして以下のような独自コンフィグファイルが格納されており、バグらせずにパースできる自信がなかったため、初期リリースからは断念しました。
https://raw.githubusercontent.com/masahiro331/go-lvm/main/testdata/metadata.txt
Filesystem層 & File層
Filesystem層は EXT4やXFS、ZFSといったファイルシステムのバイナリを解析する層です。 公開されている仕様書をもとに実装する簡単なお仕事です。
Filesystemの解析は Goの 1.16からリリースされている io/fs インターフェースを満たすように感じに実装する方針にしました。
詳細を書こうと思ったのですが、説明することが多すぎたので、いつか個別に記事を書きます。(おそらく書かない)
作ったライブラリ
xfsの実装については仕様書を見てもよくわからない... ということが多かったので、LinuxリポジトリにあるXFSのコードを参考にしつつ実装しました。
参考にしつつと言いますが、C言語が読めないマンのため、正直なにもわからないと思いつつ雰囲気で書いてました。
ここまでの実装を全て連結させることで圧縮されている仮想マシンイメージを透過的にSeekできるようになります。もっと言えば、512KB毎に圧縮されているVMDKに対して fs.WalkDir ができます。すごい!
苦労したこと&学び
正直ここから本題?みたいなところあります。
処理が重すぎる問題
Trivyでは度々メモリを使いすぎてOOMが発生しているぞ!というIssueが立ち上がります。 そのため、今回の実装でもSeekできるように実装し極力メモリを利用しないように実装しました。当初の実装では 数MB程度のメモリ消費量で仮想マシンイメージを透過的にスキャンできていましたが、死ぬほど処理が遅かったです。
原因としては、ReadAt() 関数が実行されるたびに仮想ディスクを部分的に解凍する処理が発生することです。
例えば、 redhat.vmdk の中に存在する Disk partition 1 内の EXT4 内の /etc/os-release を取得する処理では以下のような手続きが発生します。
- vmdkのヘッダをパースして仮想ディスクのブロックツリーを作成
- 2048 bytes 程度に存在するGPTもしくはMBRをパース(解凍が必要)
- MBRのパース結果をもとに Disk Partition 1 の開始Offsetから 2048 bytesを取得(解凍が必要)
- EXT4のヘッダ(スーパーブロックと言われるもの)をパース(解凍が必要)
- ヘッダに記載の root inode (
/ディレクトリのこと)をパース(解凍が必要) /ディレクトリの配下にあるファイルもしくはディレクトリの情報を取得 (解凍が必要)/etc/ディレクトリのinodeをパース (解凍が必要)/etc/ディレクトリの配下にあるファイルもしくはディレクトリの情報を取得 (解凍が必要)/etc/os-releaseの inodeをパース(解凍が必要)/etc/os-releaseのデータ領域を読み込む(解凍が必要)
はい。めちゃめちゃ解凍させます。これを ルートディレクトリから再帰的に全てのディレクトリを探索した日には処理が終わらないことが目に見えてます。
実際に当時の最初の実装で pprof をとった時のデータがこちらです。

一つの仮想マシンをスキャンするだけで、30分近くかかりました。
複数の改善を費やしたのですが、最も大きな改善となったのはキャッシュ利用です。(当たり前に早くなる)
問題点としては主に2つありました。
- 再帰的に探索する際、毎回 root inode から 特定のinodeを辿るため 同じ inodeを頻繁に参照する。しかし毎回解凍している。
- io.Reader で読み込ませるため、4096 bytes のデータを読み込む際、512 bytes のバッファで読まれると 同じ inode のデータに対して 複数回の参照が発生するが、毎回解凍している。
これらに対する打ち手として、頻繁に参照されやすいinodeがキャッシュされるように LRUキャッシュ を用いて改善しました。キャッシュのメモリは 64MB程度に収まるよう設計しています。 その結果、以下のような結果になりました。

1916 Sec から 6.66 Sec の圧倒的改善です。正直いろんなキャッシュアルゴリズムを検証しようと思いましたが、圧倒的結果に満足してしまったので試してないです。
仕様書の英語が読めない
今回の機能を開発するために以下の仕様書を読んでました。
- https://www.vmware.com/app/vmdk/?src=vmdk
- Ext4 Disk Layout - Ext4
- http://ftp.ntu.edu.tw/linux/utils/fs/xfs/docs/xfs_filesystem_structure.pdf
- [MS-VHDX]: Virtual Hard Disk v2 (VHDX) File Format | Microsoft Learn
- Hard Disk Drive Basics - NTFS.com
自分はTOEIC 245(確率に負ける男)なので、英文法すらわからずDeepLを多用しながら読んだのですが、大事な部分が翻訳で消えていたり、うまく翻訳されないなど無限に苦労をしていました。
途中は英語を読まずにバイナリデータを見ながらエスパーして仕様書で答え合わせをするといったムーブをしていました。
なんとか実装できた理由として、C言語の構造体とバイナリデータをもとに実装を推測することで、わからない英語を補完できたことにあります。英語が苦手な方はとにかくコードを読みながら実装をイメージすることが仕様書を読む秘訣かなと思います。
とにかく人に頼る
これは学びなのですが、仕様書を読んでも実装を読んでもわからないことはあります。
その道のプロっぽい人に頼ることが重要です。
自分の中では困ったら周りの人に頼るというのは、かなり当たり前の感覚だったのですが、ファイルシステムや仮想マシンの実装に詳しい人などは周りにいなかったため頼ることもできずに非常に苦労していました。
終わらない実装に限界を迎えた時に、XFSのブログを書いている外国人の方を見かけたのでダメ元でDMしたところ問題が解決しました。

困ったら人に頼るというのは、自分が知っている人だけではなく、視野を広げて世界の誰かに頼るのもいいかもしれません。
巨大なバイナリファイルを読むのが辛い
ファイルシステムのパーサーを書いている時などは野良の仮想マシンイメージを解凍して、生ファイルシステムのデータを見ながら実装していたのですが、60GB のバイナリデータを開くのに苦労していました。
自分は mac ユーザなのですが、いい感じのバイナリビューワーがないなと思いつつ less & xxd などで当初は頑張っていたのですが、無限に辛い思いをしていました。
また、仮想ディスクを自前のパーサで解凍した場合と、7zipなどで解凍した場合に512byteだけサイズがズレちゃう問題など巨大バイナリデータのdiffが取りたい欲がありそれらに対応した即席のバイナリビューワーなどを作りました。
なぜかソースコードをpushし忘れたまま手元のリポジトリが消失したので、first commitで止まってます。(いつか作り直す)
のちに知ったのですが、 xxdでオフセットが指定できるので xxd + lessだけでも十分なビューワーになります。
感謝の念(一番大事)
このPRを作る上で、めっちゃ頑張った!!と言いたいのですが、Trivyのメンテナーである knqyf263 さんには多大なご支援をいただきました。
ちなみにこのリリースのためにハードコアな労働をした結果、反動で体調を崩しています
— イスラエルいくべぇ (@knqyf263) 2022年12月2日
いけてない処理をリファクタリングしてくださったり、テストしていただいたり...
また、メイン機能であるAMIスキャンはEBSスキャンの機能を応用すればサクッと開発できる機能だったのですが、自分はそれに気がつくことができず、 knqyf263 さんのアイデアでシュッと実装してくださったりなどがありました。


ちなみに僕はリリース日に北海道へ温泉旅行してました。
最後に
恥ずかしいので、ほとんどの人が読まないであろう一番下にポエムを書きます。
この機能を開発する上で、自分は「何者かになれるのかな?」と考えながら実装していました。
ありがたいことに、自分の周りには社内外問わず本当に優秀な方が多く、見せかけの肩書きや看板ではなく、自らの実力や魅力で世界に存在を証明していて眩しいばかりです。
自分にはそう言ったものがなく、自分は何者でもない凡夫だなと思う毎日です。
re:Invent中という事でAMIスキャンをリリースしました。AMI IDを渡すだけで脆弱性スキャンできます。MBR/GPTやXFS/EXT4などをパースするいかつい実装で多分世界で初めてVMイメージを静的解析するスキャナーです。@kumagami331 のSecHack365での成果を使わせてもらっています。https://t.co/sWRutBvuW0
— イスラエルいくべぇ (@knqyf263) 2022年12月2日
この開発はツイートにも書いていただいている通り、おそらく世界で初めてVMイメージを静的解析するスキャナーを作るという自分の実力を超える機能でした。「仏も昔は凡夫なり」と言ったり言わなかったりしますが、この開発を通じて「凡夫」から「何者か」になれるかなという淡い期待があります。
「何者か」になれたか結果が出るまでには、まだまだ時間も努力も必要だと思います。
まだ「リリースしただけ」であってより多くの人に利用してもらえるように一つ一つ課題を解決していこうと思います。
今年でエンジニア歴が7年を迎えるんですが、自分はまだまだ初心者の域をでない凡夫だなと痛感するばかりです。これくらいの機能を修正なしでマージされるぐらいのエンジニアになりたいと思った年末でした。
TrivyでCycloneDXを出力するように対応してみた(SBOM)
Trivy で CycloneDX と呼ばれる SBOM の仕様を実装しましたので、備忘録も含めて CycloneDX の仕様からどのような意図で、Trivy に実装を行なったか記載しようと思います。
概要
SBOM は Software Bill of Materials の略称になっており、あるソフトウェア, 製品を構成するコンポーネントを網羅的に記述するものです。
SBOM とは?と説明を書くのに指が止まってしまったので、Linux Foundationの What is SBOM? を参考に説明します。
A Software Bill of Materials (SBOM) is a complete, formally structured list of components, libraries, and modules that are required to build (i.e. compile and link) a given piece of software and the supply chain relationships between them. These components can be open source or proprietary, free or paid, and widely available or restricted access.
文中のSBOMとは?の問いにはこのように記載されています。 「特定のソフトウェアをコンパイルするために必要なコンポーネント、ライブラリ、モジュールを網羅的に構造化して記したものであり、それらのサプライチェーン関係を示したもの。」
要はソフトウェアをモジュール単位に分割し、OS・ライブラリの依存関係・メタデータを記した、透明性の高いドキュメントを作りましょうということかと思われます。 またこのメタデータには脆弱性情報なども含まれており、Trivy の解析結果を余すことなく利用できます。
SBOM はあくまで考え方であり、実際のフォーマットは主に3つ存在します。
- SPDX
- CycloneDX
- SWID
SPDX は Linux Foundation が推進している SBOM であり、 CycloneDX は OWASP を源流とする CycloneDX Core Working Group が推進している SBOM フォーマットです。 SWID に関しては NIST が推進している SBOM らしいのですが、そもそも SBOM だったのか...?という気持ちです。
今回のブログでは Trivy で CycloneDX に対応した話を書きます。
なぜ CycloneDX なのか
SPDX を対応するか CycloneDX を対応するかで迷ったのですが、 OWASP の方が積極的に CycloneDX について情報提供してくださったりなど、コミュニティとして関わりやすかったので、まずはCycloneDXから対応することになりました。
CycloneDX の仕様について
CycloneDX は GitHub 上で仕様書が管理されており、 公式ページで内容を確認することができます。
https://cyclonedx.org/ https://github.com/CycloneDX/specification
CycloneDX の BOM は XML もしくは JSON で記述され主要なものとして metadata, components, dependencis の3つのセクションに分けられます。
<?xml version="1.0" encoding="UTF-8"?> <bom xmlns="http://cyclonedx.org/schema/bom/1.2" version="1" serialNumber="urn:uuid:7ccad4d5-9c07-469a-990f-5f639a5f0e80"> <metadata> ... </metadata> <components> ... <dependencies> ... </dependencies> </bom>
Metadata について
metadata には、この SBOM は何を対象にして作られたものなのか?について記述し、また SBOM を作成するために利用したツールなども含まれます。 そのほかにも製造元や、サプライヤーの情報なども含めることができます。
https://cyclonedx.org/use-cases/#packaging-and-distribution
例えば Trivy でコンテナの解析結果を記載するなら以下のようになります。
<metadata>
<timestamp>2021-06-15T16:38:48Z</timestamp>
<tools>
<tool>
<vendor>aquasecurity</vendor>
<name>trivy</name>
<version>dev</version>
</tool>
</tools>
<component type="container">
<name>centos:8</name>
<version>sha256:dbbacecc49b088458781c16f3775f2a</version>
</component>
</metadata>
Components について
CycloneDXには Component と呼ばれる、ソフトウェアを構成する部品を定義しています。現時点では以下のコンポーネントが定義されています。
- Application
- Container
- Device
- Library
- File
- Firmware
- Framework
- Operating System
- Service
https://cyclonedx.org/use-cases/#inventory
Components には Trivy で解析し発見された OS, Library, Application などを記述していきます。
解析対象がコンテナイメージだった場合は以下のような Components になります。
<components>
<component type="operating-system">
<bom-ref>centos:8 (centos 8.3.2011)</bom-ref>
<name>centos</name>
<version>8</version>
</component>
<component type="application">
<bom-ref>/home/hogehoge/Pipfile.lock</bom-ref>
<name>/home/hogehoge/Pipfile.lock</name>
</component>
<component type="library">
<bom-ref>pkg:rpm/centos/acl@2.2.53-1.el8?arch=x86_64</bom-ref>
<name>acl</name>
<version>2.2.53-1.el8</version>
<purl>pkg:rpm/centos/acl@2.2.53-1.el8?arch=x86_64</purl>
</component>
<components>
Application コンポーネントには検知時に発見された Lock ファイルなど依存するライブラリの元を記述していきます。 また各 Component には SBOM 内でユニークな bom-ref を記述する必要があり、これが Component 間の依存関係を記述するのに用いられます。
Dependencies について
Dependencies にはコンポーネント間の依存関係を記述します。 例えば operating-system コンポーネントに acl ライブラリがインストールされていると表現する場合は、以下のように記述します。
<dependency ref="centos:8 (centos 8.3.2011)"> <dependency ref="pkg:rpm/centos/acl@2.2.53-1.el8?arch=x86_64"/> </dependency>
ref の部分に先ほど各コンポーネントで定義した bom-ref を利用します。
カスタムプロパティについて
ここで少し余談ですが、CycloneDX ではコンポーネントに対して、カスタムプロパティと呼ばれる Key-Value型のメタデータを付与することができるのですが、この Key にベンダーのNamespace が入れられるようになっています。
以下は Operating-system コンポーネントに Trivy で利用したいプロパティを埋め込んだ例です。
<component type="operating-system">
<name>centos</name>
<version>8.4.2105</version>
<properties>
<property key="aquasecurity:trivy:Class" value="os-pkgs"/>
<property key="aquasecurity:trivy:Type" value="centos"/>
</properties>
</component>
この Namespace は CycloneDX で管理されており、申請ベースで登録することで信頼性のあるプロパティとみなされます。
開発時には知らなかったのですが、 CycloneDX の方が教えてくださりなおかつ 「Namespace 取ったよー」と申請までやってくださり、本当に助かりました。
Add Aqua Security namespace reservation · CycloneDX/cyclonedx-property-taxonomy@2ee5194 · GitHub
Trivy での実装
Trivy ではコンテナイメージやファイルシステムなどの解析結果を先ほどのコンポーネントに当てはめて記述していきます。
CycloneDX には基本的に出力する SBOM としての Requirements はなく、「〇〇が SBOM として出力されていること」などの要件はありません。 そのため、 Trivy では持ちうる情報を可能な限り出力することを目的としました。
Trivy を用いてコンテナを解析した得られる情報は大きく分けて4つになります。
コンテナの情報
- コンテナの名前とバージョン
OSの情報
- OS の種別とバージョン
アプリケーションライブラリ
- OS にインストールされているライブラリ
- アプリケーションの依存関係ファイル
- Go 言語の実行可能バイナリ
- Jar, War などのアーカイブ
脆弱性情報
コンテナの情報について
コンポーネントの種別は Container を利用し、コンテナ名、コンテナのバージョン、コンテナの sha256 のハッシュ値を出力します。 Trivy で出力すると以下のようになります。
"component": {
"type": "container",
"name": "centos",
"version": "sha256:5d0da3dc976460b72c77d94c8a1ad043720b0416bfc16c52c45d4847e53fadb6",
"properties": [
{
"name": "aquasecurity:trivy:SchemaVersion",
"value": "2"
},
{
"name": "aquasecurity:trivy:Digest",
"value": "centos@sha256:a27fd8080b517143cbbbab9dfb7c8571c40d67d534bbdee55bd6c473f432b177"
},
{
"name": "aquasecurity:trivy:Tag",
"value": "centos:latest"
}
]
}
正直、特に説明することもないです。
OS の情報について
OS の種別(CentOS や Alpine など)やバージョンについては Operating-System のコンポーネントを使用し、定義しています。 Trivy で出力すると以下のようになります。
{
"bom-ref": "centos (centos 8.4.2105)",
"type": "operating-system",
"name": "centos",
"version": "8.4.2105",
"properties": [
{
"name": "aquasecurity:trivy:Type",
"value": "centos"
},
{
"name": "aquasecurity:trivy:Class",
"value": "os-pkgs"
}
]
},
ここも正直、特に説明することもないです。
アプリケーションライブラリについて
OS にインストールされているライブラリや、アプリケーションライブラリ(pip, bundler など)については Library コンポーネントを利用しています。
CycloneDX では Library の記述方法として PURL を推奨しているため、こちらの仕様に則ってパッケージ情報を変換していきます。
PURL の仕様について少しだけ補足します。 PURL は以下のような URL 形式でパッケージを表現します。
scheme:type/namespace/name@version?qualifiers#subpath
例えば Java の spring パッケージを Trivy で表現するなら以下のようになります。
pkg:jar/org.springframework/spring-core@5.0.1.RELEASE
Maven のグループIDを namespace とし、 アーティファクトID を name にしています。
Trivy では namespace が存在しない PURL もありえます。 本来は GitHub のユーザ名や組織名などを用いるのですが、Ruby の Bundler などはそれらの情報を持ちません。 そのため rails などを PURL に変換するとこのようになります。
pkg:bundler/rails@6.1.4.1
また、 OS のパッケージなどは バージョンや名前だけではなく、 エポックやアーキテクチャなどもパッケージの一意性に関わってくるため qualfiers を利用して表現します。
CentOS の bash を表現する場合は以下のようになります。
pkg:centos/bash@4.4.19?arch=x86_64&release=14.el8&src_name=bash&src_release=14.el8&src_version=4.4.19
最終的には以下のような形で出力します。
{
"bom-ref": "pkg:centos/acl@2.2.53?arch=x86_64&license=GPLv2%2B&release=1.el8&src_name=acl&src_release=1.el8&src_version=2.2.53",
"type": "library",
"name": "acl",
"version": "2.2.53-1.el8",
"licenses": [
{
"expression": "GPLv2+"
}
],
"purl": "pkg:centos/acl@2.2.53?arch=x86_64&license=GPLv2%2B&release=1.el8&src_name=acl&src_release=1.el8&src_version=2.2.53",
"properties": [
{
"name": "aquasecurity:trivy:LayerDiffID",
"value": "sha256:74ddd0ec08fa43d09f32636ba91a0a3053b02cb4627c35051aff89f853606b59"
}
]
},
Trivy では Package の License 情報を取得することが可能なため、それらの情報なども付与しています。
また、 bom-ref には purl を利用しており、これは CycloneDX の仕様書でも推奨されている表現になります。
脆弱性情報について
脆弱性情報については、現在 CycloneDX が XML の形式しか対応していないため、 Trivy では未対応になります。
CycloneDX を対応するための PR に CycloneDX の標準化チームの議長さんがコメントをくださり、 CycloneDX 1.4 で json 対応が追加されるそうですので、気長に待ちたいと思います。

https://github.com/aquasecurity/trivy/pull/1081#discussion_r686905904
また、 CycloneDX での脆弱性の仕様を現在、拡張しており Draft版のPRが既にできあがっています。
ここまでが Trivy での実装についてとなります。
感想
この日本で誰も読まない(興味ない)だろうブログを書いてみましたが、CycloneDX がいつか流行った時に「こいつ... こんな前からやっていたのか 恐ろしい子...」みたいになればいいなと思います。
自分は文章を書くのが苦手で、この文量でも死ぬほど面倒でしたが、エンジニアの技能として文章での表現力はとても重要だと聞いたので、今後はもう少し習慣的に書こうと思います。
追記
アドカレにマージが間に合いませんでした(2021/12/22) github.com
RPMDBを解析した話
OSS開発をしている中で、RPMDBの実装を理解する必要があり調べたことを記事に残そうと思います。
世界にこの記事を読んで嬉しい方は、万に一人もいないと思います。
今回の記事はRPMDBを解析する背景と、初めてC言語で書かれた実装を真面目に解析した話をしようかなと思います。
背景
個人的に Trivy というコンテナ脆弱性ツールの開発に少しだけ参加しており、その中で以下のようなIssueが立ちました。
Issueを要約すると、「Red Hatの8系で脆弱性が誤検知している」というものです。
原因としては、Red Hat 8/Fedora 28から導入されたModularityという機能によって一部のパッケージのバージョン体系が変更されたことによって脆弱性検知が誤作動を起こしました。
興味がある方のために少し詳しく記載しますが、興味のない方は飛ばして 「本題」を読んでください。
始めに、Trivyのコンテナイメージの脆弱性検知プロセスについてざっくり説明します。
- コンテナイメージを取得
- コンテナイメージからOSを識別するために必要なファイルを抽出
- OS毎のパッケージ管理システムのデータベースファイル(造語)を抽出
- データベースファイルを解析し、インストールされているパッケージ情報を取得
- 脆弱性データベースとパッケージ情報を突合し脆弱性を検知
1と2と3の解説はスキップします。
4.についてはRed Hatの場合は /var/lib/rpm/Packages ファイルを解析することによってインストールされたパッケージ情報を取得できます。
詳細は Trivyの開発者である、@knqyf263 のブログに触れられていたはずなのでこちらを読んでください...
5.について説明します。
まず始めに、Trivyで利用するRed Hatの脆弱性データベースには基本的に脆弱性が影響するバージョンが記載されています。
例えば CVE-2018-7584の脆弱性を例に挙げます。
{
"product_name": "Red Hat Enterprise Linux 7",
"release_date": "2020-03-31T00:00:00Z",
"advisory": "RHSA-2020:1112",
"package": "php-0:5.4.16-48.el7",
"cpe": "cpe:/o:redhat:enterprise_linux:7"
},
↑は脆弱性情報の一部を抜粋していますが、 意味としては 「RHSA-2020:1112(CVE-2018-7584) は phpの 0:5.4.16-48に影響する」になります。
つまり phpの5.4.16-48以下のバージョンは全て、CVE-2018-7548に影響し、5.4.16-48より大きいバージョンでは修正されているということです。
Trivyはこの脆弱性情報を元に現在コンテナにインストールされているパッケージと脆弱性情報のバージョンを比較して脆弱性検知を行っています。
次に同じ脆弱性の情報として以下のようなことが記載されています。
{
"product_name": "Red Hat Software Collections for Red Hat Enterprise Linux 7.5 EUS",
"release_date": "2019-08-19T00:00:00Z",
"advisory": "RHSA-2019:2519",
"package": "rh-php71-php-0:7.1.30-1.el7",
"cpe": "cpe:/a:redhat:rhel_software_collections:3"
},
これは phpの7.1.30-1 以下のバージョンに RHSA-2020:1112(CVE-2018-7584) が影響するという脆弱性情報です。
この場合一見すると先ほどの脆弱性情報と矛盾が生じます。
xxx <= 5.4.16-48 xxx <= 7.1.30-1
例えば 5.4.17 は一つ目の情報だと修正済みに見えますが、2つ目の情報を元にすると影響しそうな気がします。
しかし実際は問題ありません。 なぜなら、パッケージが異なるからです。
一つ目は php、二つ目は rh-php71-php という同じphpに見えてRed Hat上では明確に異なるパッケージとして認識されるからです。
Red Hat 7系以前では、phpをインストールすると必ず 5.4.xx がインストールされ、rh-php71をインストールすると 7.1.xx がインストールされる世界でした。
しかし、Red Hat 8系からこの仕様が Modularity によって変わりました。
ざっくりいいますと、 Modularという概念によって、phpというパッケージで 7.2.xx や 7.3.xx、 7.4.xx がインストールできるようになりました。
これによってphp 7.4の脆弱性情報も php 7.2 の情報も同じ php パッケージとして認識されるようになり、既存の脆弱性検知手法だと、7.2の修正バージョンが 7.4の脆弱性情報によって脆弱なバージョンとして扱われることになってしまいました。
解決策として、 Modular は既存の脆弱性検知ロジックとは異なる手法で検知する必要があります。
しかし既存の Trivy が利用しているライブラリでは、インストールされているパッケージが既存手法でインストールされたのか、Modularによってインストールされたのか判断することができません。
ちなみに rpm の以下のコマンドでModuarかどうか判断が可能です。
# centos:8でもModularが利用できます。
$ docker run --it --rm centos:8 /bin/bash
$ dnf install php
$ rpm -q php --qf "%{NAME} %{VERSION} %{MODULARITYLABEL}\n\n"
php 7.2.24 php:7.2:8020020200507003613:2c7ca891
$ rpm -q glibc --qf "%{NAME} %{VERSION} %{MODULARITYLABEL}\n"
glibc 2.28 (none)
phpは Modular でインストールされ、 glibcは既存手法でインストールされています。
ということで、Trivy でrpmコマンドにおける MODULARITYLABEL (modularのタグ)を取得するための実装をしました。
ここから本題に入ります。
本題
TrivyではRed HatベースのOSにインストールされているパッケージを解析するために rpmdbの解析ライブラリを用いています。
ライブラリの説明などは省略して、rpmdbの説明をしたいと思いますので、雑にPRだけ貼っておきます。
https://github.com/knqyf263/go-rpmdb/pull/4
このPRを書くためにrpmのソースコードを読んだのでそこで学んだことをまとめます。
実装
自分は今回初めてC言語で書かれた実装を真面目に解析したので、どういったプロセスで解析したのかも書こうかなと思います。
まず、rpmコマンドで普通にModularの情報を取得するにはどうすればいいのか?それはどうやって動作しているのかを調べました。
実行コマンド
rpm -qa --qf "%{MODULARITYLABEL}"
このコマンドでModularの情報を取得できることはわかったので、これを元に実装を調査し、同じプログラムを書けばいいと考えました。
コマンドからの実装を調査
始めに、プログラムの開始地点を探します。 ここですね。 https://github.com/rpm-software-management/rpm/blob/master/rpm.c#L61
この時はまだGDBというツールを使ったことがなかったので、rpmをビルドして脳死printfデバッグをしました。
俺もrpmをbuildしてdebugしたい!!って人用にbuild用のdockerを公開しています。
https://github.com/masahiro331/build-rpm-docker
rpmdbをパースする重要な処理がここから始まっていることがわかりました。
https://github.com/rpm-software-management/rpm/blob/rpm-4.15.1-release/lib/header.c#L2040
正確にはこの2行を実行してパースしたHeaderの中に欲しい情報が入っています。
/* Sanity checks on header intro. */
if (hdrblobInit(b, bsize, 0, 0, &hblob, &buf) == RPMRC_OK)
hdrblobImport(&hblob, (flags & HEADERIMPORT_FAST), &h, &buf);
ということでここから各関数での実装をつらつら書こうかなと思います。
RPMDBのデータ構造だけみたいんじゃという方は最後のほうまで飛ばしてもらえれば、雑な構造図だけ貼ってます。
hdrblobInit
https://github.com/rpm-software-management/rpm/blob/rpm-4.15.1-release/lib/header.c#L1970
長いコードではないので貼っちゃいます。
rpmRC hdrblobInit(const void *uh, size_t uc,
rpmTagVal regionTag, int exact_size,
struct hdrblob_s *blob, char **emsg)
{
rpmRC rc = RPMRC_FAIL;
memset(blob, 0, sizeof(*blob));
blob->ei = (int32_t *) uh; /* discards const */
blob->il = ntohl(blob->ei[0]);
blob->dl = ntohl(blob->ei[1]);
blob->pe = (entryInfo) &(blob->ei[2]);
blob->pvlen = sizeof(blob->il) + sizeof(blob->dl) +
(blob->il * sizeof(*blob->pe)) + blob->dl;
blob->dataStart = (uint8_t *) (blob->pe + blob->il);
blob->dataEnd = blob->dataStart + blob->dl;
/* Is the blob the right size? */
if (blob->pvlen >= headerMaxbytes || (uc && blob->pvlen != uc)) {
rasprintf(emsg, _("blob size(%d): BAD, 8 + 16 * il(%d) + dl(%d)"),
blob->pvlen, blob->il, blob->dl);
goto exit;
}
if (hdrblobVerifyRegion(regionTag, exact_size, blob, emsg) == RPMRC_FAIL)
goto exit;
/* Sanity check the rest of the header structure. */
if (hdrblobVerifyInfo(blob, emsg))
goto exit;
rc = RPMRC_OK;
exit:
return rc;
}
重要なのは引数に渡ってきている hdrblob_s構造体のblobポインタに値を埋めていく作業です。
typedef struct hdrblob_s * hdrblob;
struct hdrblob_s {
int32_t *ei;
int32_t il;
int32_t dl;
entryInfo pe;
int32_t pvlen;
uint8_t *dataStart;
uint8_t *dataEnd;
rpmTagVal regionTag;
int32_t ril;
int32_t rdl;
};
blob->eiにはデータの先頭ポインタ
blob->il には index Length
blob->dl には data Length
blob->pe には 先頭の entryInfo_s らしきもの
entryInfoの構造体をみていると、どうやらなんらかのデータの型やサイズ、開始位置が記述されてそう
struct entryInfo_s {
rpm_tag_t tag; /*!< Tag identifier. */
rpm_tagtype_t type; /*!< Tag data type. */
int32_t offset; /*!< Offset into data segment (ondisk only). */
rpm_count_t count; /*!< Number of tag elements. */
};
blob->pvlen には全体のサイズ
blob->dataStart は データ部の開始
少し難しいのですが、 pe[il]と読み替えてよさそうで、どうやら il個あるentryInfoの最後のアドレスを指し示してそう
blob->dataEnd は dataStart + dlなのでdata部の最後っぽさ
ここまで文字で書きましたが、いったん図に落として整理してみたいと思います。

ただ、まだ重要な行が4行ほど残ってます。
if (hdrblobVerifyRegion(regionTag, exact_size, blob, emsg) == RPMRC_FAIL)
goto exit;
/* Sanity check the rest of the header structure. */
if (hdrblobVerifyInfo(blob, emsg))
goto exit;
最初は構造体をパースするにあたり、Verify**みたいな関数名だったので、無視していたのですが内部で非常に重要な値を取っているのでみていきます。
hdrblobVerifyRegion
https://github.com/rpm-software-management/rpm/blob/rpm-4.15.1-release/lib/header.c#L1787
処理の中に重要な処理がいくつか紛れ込んでいるのですが、今回は一つだけ一番大事なやつをメモ書いておきます
一部抜粋
struct entryInfo_s trailer, einfo;
memset(&trailer, 0, sizeof(trailer));
regionEnd = blob->dataStart + einfo.offset;
(void) memcpy(&trailer, regionEnd, REGION_TAG_COUNT);
regionEnd += REGION_TAG_COUNT;
blob->rdl = regionEnd - blob->dataStart;
ei2h(&trailer, &einfo);
/* Trailer offset is negative and has a special meaning */
einfo.offset = -einfo.offset;
/* Some old packages have HEADERIMAGE in signature region trailer, fix up */
if (regionTag == RPMTAG_HEADERSIGNATURES && einfo.tag == RPMTAG_HEADERIMAGE)
einfo.tag = RPMTAG_HEADERSIGNATURES;
if (!(einfo.tag == regionTag &&
einfo.type == REGION_TAG_TYPE && einfo.count == REGION_TAG_COUNT))
{
rasprintf(buf,
_("region trailer: BAD, tag %d type %d offset %d count %d"),
einfo.tag, einfo.type, einfo.offset, einfo.count);
goto exit;
}
/* Does the region actually fit within the header? */
blob->ril = einfo.offset/sizeof(*blob->pe);
処理を説明する前に einfoについて説明します。
einfoは先ほどの hdrblobInit でil, dl, pe の順番にパースした時のpeが入っています。
便宜的にこの 先頭のeinfo(entryInfo_s) を「Regionメタデータ」と呼びます
Regionメタデータの Offset値とdataStartを足した場所に trailerと呼ばれる entryInfo_s構造体が存在するようです。
※ REGION_TAG_COUNTはentryInfo_sのサイズ
trailerを取得し、その値を用いることで最後の ril値を計算することができます。
何気なく計算しているril値ですが、非常に重要な値でした。
// trailerをeinfoに代入しなおしているため einfo.offsetと記述されている blob->ril = einfo.offset/sizeof(*blob->pe);
rilは region Index Lengthの略だと思うのですが、値をみていると、peの配列の特定の番地を示す値のようです。
ここまでの実装を再度図に起こします。

hdrblobVerifyInfo
こちらは本当に値の検証だけなのでスキップします。
hdrblobImport
ここまでで、パース処理のhdrblobInitが終わりました。次にhdrblobImportを見ていきます。
/* Sanity checks on header intro. */
if (hdrblobInit(b, bsize, 0, 0, &hblob, &buf) == RPMRC_OK)
hdrblobImport(&hblob, (flags & HEADERIMPORT_FAST), &h, &buf);
https://github.com/rpm-software-management/rpm/blob/rpm-4.15.1-release/lib/header.c#L877
正直長いのと疲れてきたので、パパッと説明します。
初手のindexEntry構造体を宣言しています。
indexEntry entry;
どうやら、entryInfoと実際のデータとその長さを持っているみたいですね。
typedef struct indexEntry_s * indexEntry;
struct indexEntry_s {
struct entryInfo_s info; /*!< Description of tag data. */
rpm_data_t data; /*!< Location of tag data. */
int length; /*!< No. bytes of data. */
int rdlen; /*!< No. bytes of data in region. */
};
始めの if文です。あくまでも仮説ですが、互換性のために残してそうな実装です。
entry = h->index;
if (!(htonl(blob->pe->tag) < RPMTAG_HEADERI18NTABLE)) {
実際この if文に入るケースは gpg-pubkeyなどの少し特殊なパッケージをパースする際に入るので今回は無視します。
次に、elseを見ます。こちらがやっかいです。
int32_t ril;
h->flags &= ~HEADERFLAG_LEGACY;
ei2h(blob->pe, &entry->info);
ril = (entry->info.offset != 0) ? blob->ril : blob->il;
余談ですが、rpmのコードは至る所に spaceと tabが混在していて読んでいてキレ散らかしそうになります。
詳しくないんですが、こういう書き方が一般的なんですかね。。。?
戻ります。 regionメタデータ(先頭のpe)のoffsetが0ではない時、rilにはblob->rilを代入し、0の時はblob->ilを代入しています。 その後、entryの値を埋めて regionSwab関数を呼んでいます。
entry->info.offset = -(ril * sizeof(*blob->pe)); /* negative offset */
entry->data = blob->pe;
entry->length = blob->pvlen - sizeof(blob->il) - sizeof(blob->dl);
rdlen = regionSwab(entry+1, ril-1, 0, blob->pe+1,
blob->dataStart, blob->dataEnd,
entry->info.offset, fast);
if (rdlen < 0)
goto errxit;
entry->rdlen = rdlen;
if (ril < h->indexUsed) {
indexEntry newEntry = entry + ril;
int ne = (h->indexUsed - ril);
int rid = entry->info.offset+1;
/* Load dribble entries from region. */
rdlen = regionSwab(newEntry, ne, rdlen, blob->pe+ril,
blob->dataStart, blob->dataEnd, rid, fast);
if (rdlen < 0)
goto errxit;
ここら辺コードで説明するのが疲れてきたので、図に起こします。

大事なのは trailerを挟んで2回 regionSwabを実行していることにあります。 regionSwabは IndexEntries配列にデータを埋めていく作業をしてくれる関数です。
https://github.com/rpm-software-management/rpm/blob/rpm-4.15.1-release/lib/header.c#L495
少しだけ実装に気をつけたことを記述しておくと、regionSwab内でデータのサイズを計算する処理があるんですが、データの型によって実装を分ける必要があるということです。
/* The offset optimization is only relevant for string types */
if (fast && il > 1 && typeSizes[ie.info.type] == -1) {
ie.length = ntohl(pe[1].offset) - ie.info.offset;
} else {
ie.length = dataLength(ie.info.type, ie.data, ie.info.count,
1, dataEnd);
}
アクセス効率化のためにアラインメントするので、rpmdbもそれを意識したメモリ配置にしている。 データ型のサイズと実際のbinary上のデータサイズが異なるため、char型以外のデータの場合は都度計算し直す必要があります。
ここまでの処理でrpmdbをパースすることができました。 あとは本題の Modularの情報をとるだけです。
https://github.com/rpm-software-management/rpm/blob/rpm-4.15.1-release/lib/rpmtag.h#L375
indexEntry->info->tagが 5096 になるものを探して idnexEntry->dataをstringでキャストすれば完了です。
最後にこちらがPRになります。
以上、rpmdbを読んだ話でした。
あとがきてきなもの
ブログになれてないので、後半すごく辛かったです。しばらくは3行以上の日本語が読めそうにありません。
本当はもっと詳しく実装を紹介したいのですが、うまく文章が書けないなって部分や、実はまだまだ実装に対する理解度が足りないなと反省しているところです。
もう少し読み進めて随時、ブログの修正をしたいと思います。